
Infor Data Fabric
If your company is considering or has decided to leverage an Infor Cloud ERP, then it is likely you have heard of Infor Data Fabric. Infor Data Fabric is a component of Infor OS, which is a foundational service for all of their Cloud Suite ERPs. So whether you are using Infor LN or Infor M3, they both integrate with the same Infor Data Fabric.
Why is that important?
While positioned as a feature, it is worth noting that Infor Data Fabric is required. Compared to on-premises solutions, Infor Data Fabric is the primary way to get data out of your ERP. In some cases, it is positioned as the only data platform you need, suggesting you ingest non-ERP data into their data fabric.
What is Infor Data Fabric?
Before getting into specific components, it isworth noting that Infor CloudSuite is built on AWS. In fact, the majority ofInfor Data Fabric components are white-labeled AWS services with additional integrations or restrictions built in. With that said, here are some of the main pieces of the data fabric puzzle:
Components
- Data Lake: Built on top of S3
- Atlas: GUI Interface to manage files within the Data Lake
- Data Ledger: Auditing for Source to Lake Ingestion
- Availability depends on ERP and ingestion pattern
- Compass: Query Engine built on topof Athena
- DataCatalog: Metadata catalog built off AWS Glue services
- Metagraph:GUI domain data modeler to generate Data Lake Views
- Security
Considerations
ERP to Data Lake
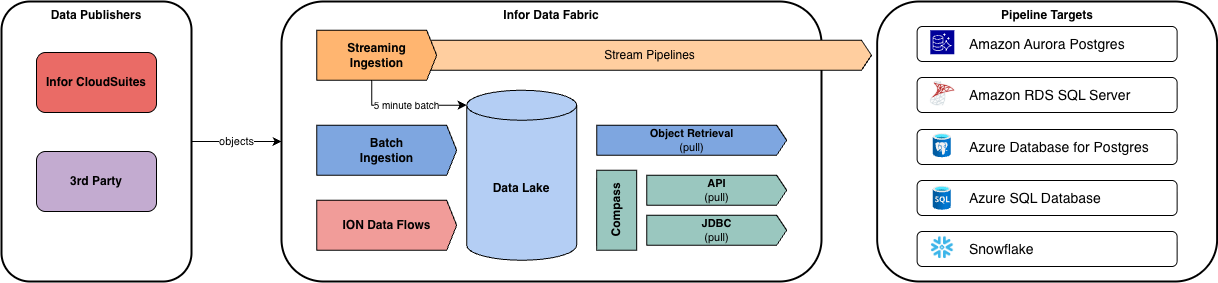
Data is replicated from the source ERP to the Data Lake through a Batch Ingestion API for the initial load and then Streaming Ingestion service for subsequent change sets. The data is ingested every 5 minutes (or 5MB object size). This data replication needs to be configured within your ERP to deliver the data to the Data Lake, also called “Data Publishing”. Originally it was done through the ION Messaging service, which was a micro-batch process where you had to setup create document flows in ION to deliver the data to the Data Lake.
If you are still using the IMS to publish data, it is recommended to migrate to the Data Lake Ingestion framework. This will simplify the architecture and items to maintain. Additionally, with IMS you need to leverage OneView to investigate Source to Target differences, which is extremely difficult. With Data Lake ingestion, Data Ledger will provide a much cleaner mechanism to have visibility of data delivery and related issues.
Separately, there is an additional add-on you can purchase which will stream the data to specific targets (for example, Snowflake) directly from the ERP. However, we generally recommend only using this for specific real-time use cases because it can have a negative effect on the performance of your ERP.
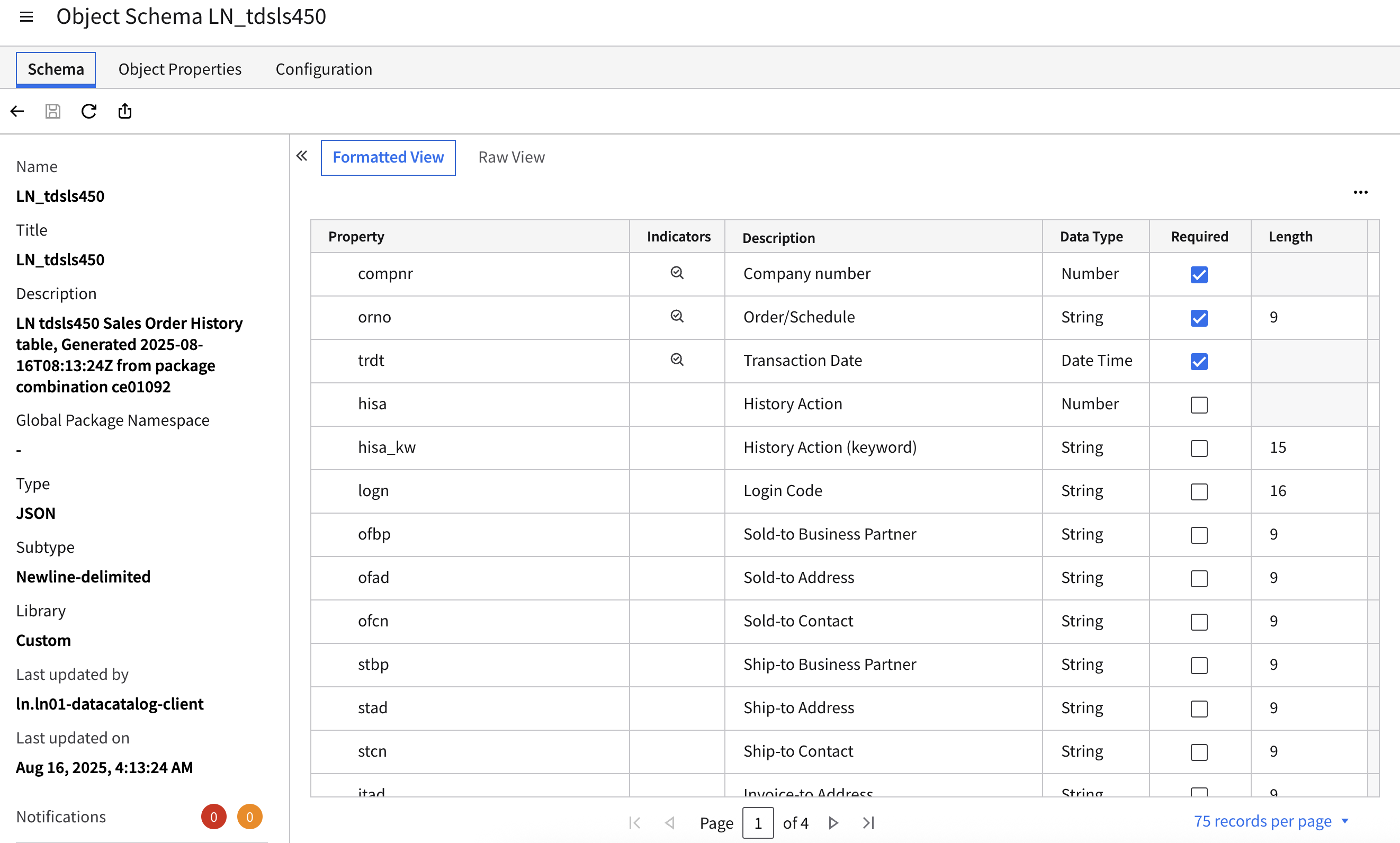
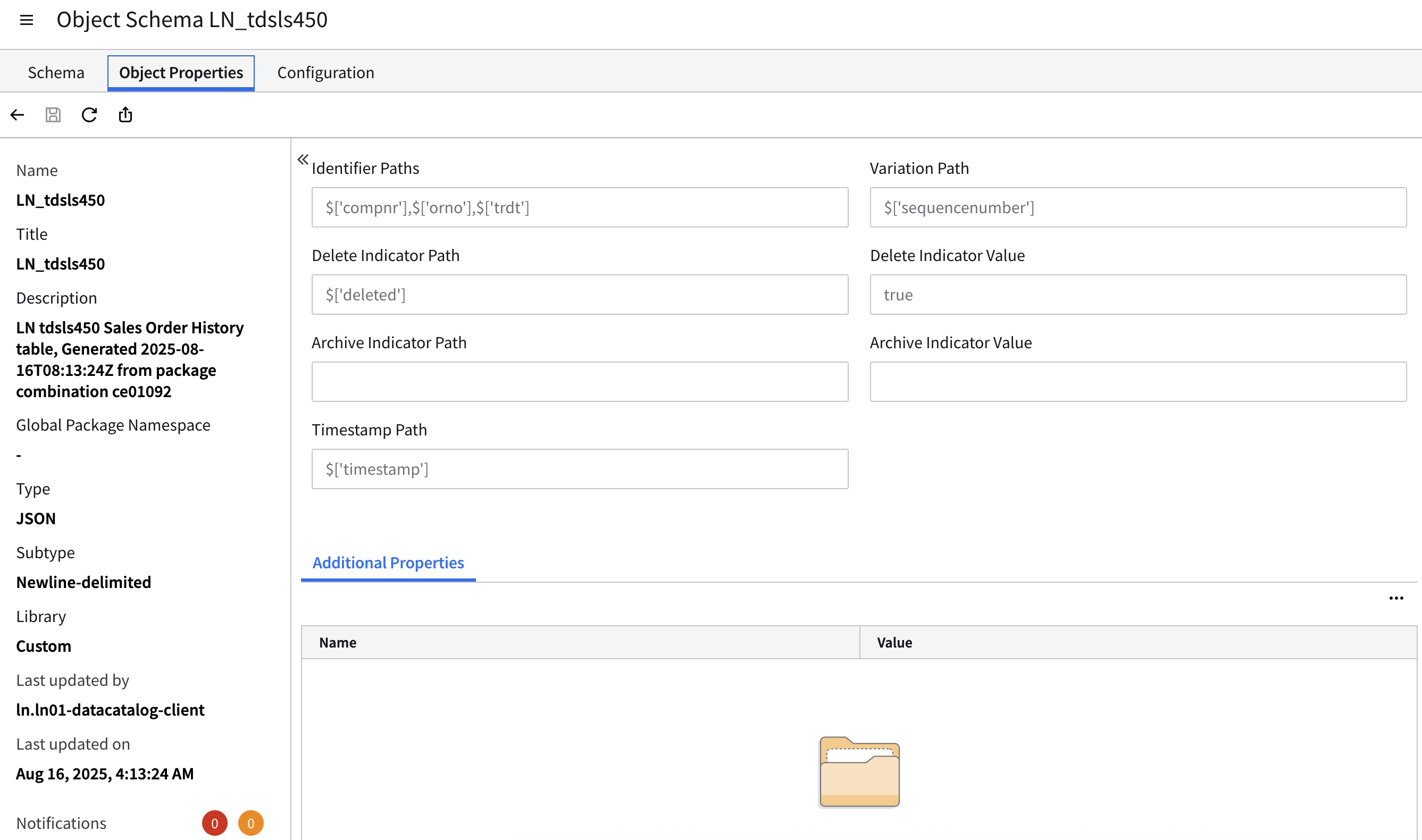
Data Catalog
Within DataFabric, there is a Data Catalog. This is specifically a technical metadata catalog. Its main purpose is to provide schema information of objects within the data lake. This is not something you would expose to a business user or even an analyst to understand the data and where it came from. It primarily is used to define the table columns and table constraints like primary key combination and metadata values like variation path and deleted indicator.
Additionally, you can use the Metagraph functionality to build out domain relationships between objects to generate Data Lake Views within the Data Catalog.
Example Screenshots:
Connecting to Data Lake
Infor exposes the data lake through a series of APIs and built-in query platform Compass. Compass is an abstraction of AWS Athena. Within the web platform, you can query the tool or you can leverage their REST API to either retrieve the Data Lake objects directly, or process a query and return a result set. Additionally, you can use their Compass JDBC driver to connect to their system.
It is worth mentioning that while it is AWS Athena under the hood, you cannot use Athena connectors to connect to Compass. This means whatever system you use to connect to Infor will need either an Infor-specific connector, the ability to leverage a custom JDBC driver, or the ability to query REST APIs.
Data Flows
While technically under Infor ION, this service enables ingestion into the Data Lake and additional features and functionalities. Data Flow is a visual workflow builder built off AWS Glue that can perform both operational and analytical duties.
One example being that you can stream data outof the Data Lake to AWS Kinesis or Kafka.
How Should You Use Infor Data Fabric?
While attempting to be pragmatic, the reality is your Infor partner will position Infor Data Fabric as an all-in-one Enterprise Data Platform. From my experience, working with multiple customers, it is not mature enough to be considered that. The features and functionality do not meet the need of most organizations. Comparing this solution to any other market leading offerings, it pales in comparison to features and functionality.
Existing Pain Points
- Without Data Ledger, Data Quality checks are near impossible.
- Compass can be slow.
- Compass caches data by creating parquet files. However, these can quickly become out of date when new data lands.
- Metagraph can be used to create views, however there is no production grade data transformation capability within the platform. Given the nature of ERP data, this is necessary.
- While there is security, it is limited in scope. For example, you cannot provide row-level security. Additionally, it is difficult to manage since it is setup manually. There’s currently no mechanism to apply security programmatically.
- Limited integrations. Unfortunately, even though its built using industry standard services, everything is abstracted. This does make sense due to the multi-tenant nature of their platform. However, this means in a lot of cases, you need to develop custom solutions against their APIs. For example, if you use a cloud BI tool, you may have to use their REST API to query Compass. This means you have to code around the JSON response vs a typical ODBC/JDBC SQLquery.
Our Recommendation
In any case, you will have to leverage Infor Data Fabric. It is the only realistic way to get the data out of your Cloud ERP. While you can pay a premium and get Streaming Pipelines, that is not currently sufficient to replace your data pipelines.
Separately,you can purchase their ETL product. The last time we reviewed this solution it was built from Pentaho Data Integration. To pay for and install an on-premises, ETL tool to query your Cloud ERP to then load into a cloud data warehouse was a perfect example of an anti-pattern.
What we recommend is treating the Infor DataFabric as a staging layer. Land the data in Infor’s Data Lake and then either stream the data out or perform batch pulls into your platform of choice.
An example architecture we've implemented
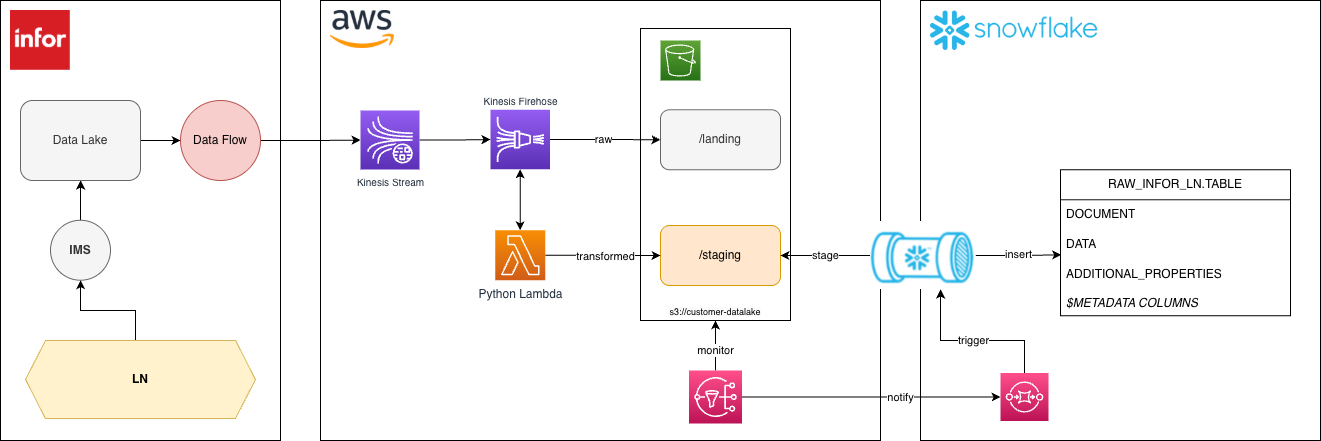
Notes
At this time, there were several features not supported by Infor or AWS which we may have leveraged if available.
- Infor Data Lake Ingestion
- Infor Kafka Connection
- AWS Firehose to Snowflake Target
Conclusion
We see Infor Data Fabric as the interface to get your Infor ERP data. If you are currently facing challenges of extracting or modeling this data, let us know! We’ve worked on Infor LN and M3 projects and have implemented a variety of solutions that fit our customers’ needs and priorities.
Reach out for a free data strategy assessment with one of our experts.
.jpg)


